背景
公共的通道服务U向各个业务方提供长连接接入层服务,完成客户端鉴权、连接建立、心跳检测、重连等功能,并且向业务方服务器端开放API接口,提供向客户端分发数据(send)、查询客户端状态等能力。 send方法的本质是向指定RocketMQ topic写入消息,再由通道服务U消费。
SD项目使用通道服务,向客户端下发游戏房间的信令,指导客户端状态切换。
故障描述
某日晚上9点多,正是app业务高峰期,收到反馈越来越多,客户端语音房间卡顿严重,表现为不能正常轮转,等待几秒到几十秒才有反应(当然更多的用户直接就退出了)。
故障排查
客户端游戏状态切换等待久,可能的原因有:
- 服务器端问题,没有及时轮转
- 服务器端正常轮转,并且向通道服务发送指令,但是客户端没有及时收到
于是兵分两路排查。
服务器端
首先,抽取几个有问题的语音房间room_id,作为跟踪。
应用日志grep <room_id>,发现
- 基本正常,但是少数延迟消息接收有问题,注册30s后的延迟消息,真正接收时间在1min以上,导致切换异常。
- 服务器端调用通道服务API,发送信令,立即返回。同时把msgId发给客户端跟踪。
对于1),明显是MQ出现问题了,联系中间件的运维,得知正在进行机房迁移,带宽有限,产生大量消息堆积……尼玛,这么大的事情为什么没有通知到业务方!
客户端
客户端拿着msgId去查询通道服务,发现通道服务真正下发消息延后了几十秒到几分钟不等。从通道服务得到的反馈是,由于MQ机房迁移,加上某个大业务方A的业务高峰,通道服务处理堆积消息,网卡流量都打爆,其他业务方是受到了不同程度的影响……
故障解决
- 挂出升级维护公告,虽然不知道效果如何~
- 等待堆积消息消费完毕。大约9点半过后,房间卡顿减少,10点左右恢复正常。
反思
首先梳理这次故障的发生流程。
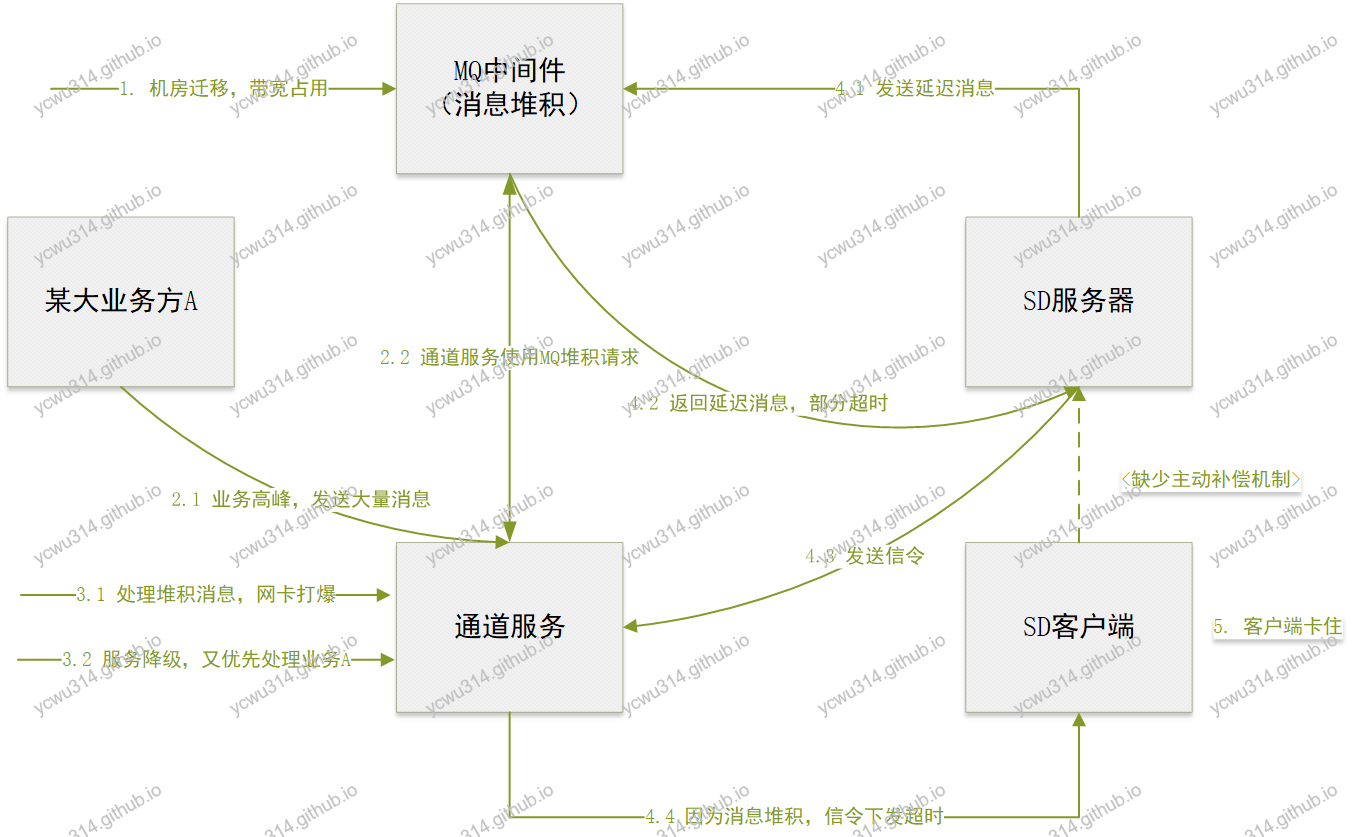
- 个别延迟消息超时,导致服务器端房间状态切换延迟
- 服务器端下发的信令,由于通道服务故障,不能及时下发到客户端
- 客户端也没有主动补偿机制,导致一旦通道服务失效,将无法恢复
此外,迁移升级的事情没有及时通知给业务方。
方案优化
增加容灾方案。
服务器端
由于严重依赖延迟消息进行异常情况的房间状态切换,一旦MQ故障,房间服务不可用。要增加备用检查机制,SLA略低,但可以保证房间在不依赖MQ的情况下也可以轮转。
- 方案:引入分布式定时任务框架,对于已经开始的语音游戏房间,注册定时任务检查
- 开发成本:中
- 收益:低。因为MQ故障属于低概率事件,产出投入比低。
- 最终实施:待定
增加备用通道
只有通道服务作为长连接服务,并且和大业务方共享底层资源。要增加被用通信通道。
- 方案:自建websocket通道,用于应急使用。服务端根据下发策略向通道服务、websocket发送信令。客户端适配双通道。
- 开发成本:中。
- 收益:高。
- 最终实施:是
客户端主动补偿机制
因为客户端强依赖信令切换状态,一旦出现信令超时或者丢失,就会切换失败,导致卡顿。此时服务器端是正常运作的。 最初设计的时候,就要求客户端必须要实现主动补偿机制,达到信令下发的推拉结合。遗憾的是,并没有。
- 方案:客户端必须要实现主动补偿机制,使用服务器端提供的接口,预期时间内收不到信令,主动查询;并且恢复。
- 开发成本:高。对原有客户端代码改动大。
- 收益:高。
- 最终实施:部分实现。