反爬虫:故事的起源
以前就想做个小站点,记录学习点滴。苦于996的生活,一直没动手。今年决定要改变现状,于是就有了这个小站,纯属自娱自乐。 期间学习SEO,也在这个站点上做实验,接入google analysis、google search console。 为了研究外链的影响,我在csdn、cnblogs也注册了账号,找了几篇文章贴过去,带上站点链接。 然后,就给自己挖坑了。

都是些什么站点呢,打开一个看看http://www.ishenping.com/ArtInfo/1377053.html

还有外链呢?别傻了,这是我保存在原文里面的。如果把这个链接去掉,就是彻底的文章搬运工了。
不过这个站点已经是比较友(ruou)好(zhi)了,更加恶心的爬虫,会把文章内部的超链接都去掉,比如这个http://www.liuhaihua.cn/archives/596486.html

更大的麻烦在于推酷也来了,爬了好几十篇文章

推酷会保留完整的格式和链接出处,这一点倒是真的。但是这个爬虫网站,反爬能力却战五渣。通过tuicool让更多文章搬运站点复制了这个小站。 爬虫文章的受害者,不是瞎说的:

这个文章是预先提交的,准备填坑。连基本的数据清洗、机器文章质量打分都没有就直接入库。爬虫文章基本不会更新的(纯属利益问题,不需要做更新),如果文中有误,即使作者修复了,也只会无脑传播出去原始爬到的版本。 于是就有了这个反爬虫系列文章。
爬虫站点的经济利益
爬虫站点是典型的流量经济。 它们本身不做内容的产出,只做内容的搬运工。文章只是个占位符,至于内容好坏和是否更新,they dont care。有的甚至连图片cdn也省了,直接使用原站的图片链接,消耗原站的流量。初级的爬虫限流不做好,容易对原站点造成流量压力,影响正常访问。 由搜索引擎引入流量,然后通过各种广告联盟获利。 在微信发达的今天,这种玩法也搬到了公众号,不过公众号平台对原创内容的保护,情况要比互联网要好一些。
反爬虫思路
脱离业务背景的解决方案就是耍流氓。
先说背景:这站点是个托管到github的静态页面,连域名都是github提供的二级域名。。。 之前考虑过买个域名,但是备案流程长,当时觉得用github托管也没什么问题,于是就愉快的使用hexo撸了几十篇文章,直到被爬虫发现。 没有服务器端能力,做反爬真心蛋疼。 但,人生在于折腾。
首先要承认,随着爬和反爬的对抗,识别爬虫越来越艰难。但是技术实施有成本问题,防住大部分低级爬虫就是了。 换位思考,爬虫站点是怎么工作的:
- 发现新链接
- 静态爬取:直接下载html文章,再做静态解析。适用于大部分静态站点,例如Hexo、Jekyll、Hugo。
- 动态爬取:使用headless浏览器,模拟打开站点,解析完整的dom树,提取文章内容。
反爬虫的方向:
- 行为检测
- 客户端特征检查
- 页面内容做混淆
- 动态加载内容
- 爬虫陷阱,返回过期内容
针对我的站点,长远规划:
- 购买域名,备案,迁移站点
- 使用nginx加流量分析、指纹分析屏蔽爬虫请求
- 图片接入cdn,简单的防盗链
短期任务:
- 联系删除已有侵权文章
- 修改文章模板,增加版权和来源声明,方便维权
- 尽量阻止爬虫获取新文章
- (静态反爬)发布过时内容
- (静态反爬)字体反爬
- (动态反爬)增加检查客户端的js,识别爬虫客户端
- 已经暴露的图片链接换名
- 图片加水印
这个系列文章主要分享我在做静态网站反爬的经历。
联系爬虫网站删除
内容都进入别人的数据库,还能怎样呢?直到看到这篇文章,感谢作者分享维权经历: 博客园原创文章防剽窃、反爬虫指南(持续更新…..)
于是我也照着做

推酷官网邮件根本不鸟人。dig一下发现站点是部署在aliyun,
# dig tuicool.com
; <<>> DiG 9.11.3-1ubuntu1.8-Ubuntu <<>> tuicool.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 59465
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 65494
;; QUESTION SECTION:
;tuicool.com. IN A
;; ANSWER SECTION:
tuicool.com. 10 IN A **这里是ip地址**
;; Query time: 33 msec
;; SERVER: 127.0.0.53#53(127.0.0.53)
;; WHEN: Sat Aug 31 16:03:17 CST 2019
;; MSG SIZE rcvd: 56
拿到ip地址之后,再用whois查询。看样子要通过阿里云举报中心投诉了。
这些爬虫站点的一大流量来源是搜索引擎。首先去全球最大的百家号搜索引擎举报侵权:

如果你真的点击进去
深感维权艰难。
虽然由于不可描述的原因,谷歌不能正常访问。但是版权制度在国外比较完善。我向google提起侵权删除页面请求: 举报涉嫌侵犯版权的行为:Google 网页搜索

一旦确认通过,在google搜索页面底部可以看到(LumenDatabase是寒蝉效应的数据库)
为了回应用户根据美国数字千年版权法案向我们提交的多项投诉,我们已从此页上移除了 2 个结果。如果需要,您可以访问 LumenDatabase.org,查看导致结果遭到移除的 DMCA 投诉内容: 投诉, 投诉.
至少还有google会认真对待我的诉求❤。
阻止爬虫获取新文章通知
我这个不知名站点,为什么文章更新不久之后,就会被爬虫站点发现并且爬取呢? 从经济的角度就直到,它们不会一直盯着各个站点,看有无更新,太消耗资源了。 它们也不需要这样操作。因为有太多简单的方式可以获取。 知名站点,例如cnblogs、csdn,就爬热门的、新发的、推荐的。 普通静态站点,一般使用模板引擎构建。爬取sitemap、归档页面就可以获取获取全量的站点文章,然后根据模板引擎的不同,获取内容数据。 例如,hexo的生成的静态站点,默认会在meta标签增加一行
<meta name="generator" content="Hexo 3.9.0">
就如nginx配置,通常会隐藏版本号提高安全性一样,这一行可以屏蔽掉。文件位置是themes\next\layout_layout.swig 。 模板引擎还有其他特征暴露身份,此处不展开了。
不过我观察发现,有的爬虫站点是从某一个时间开始爬文章,并非全量文章都爬取。很有可能是使用rss feed订阅功能,直接关注链接获取增量更新。 有了上面的分享,就简单了。
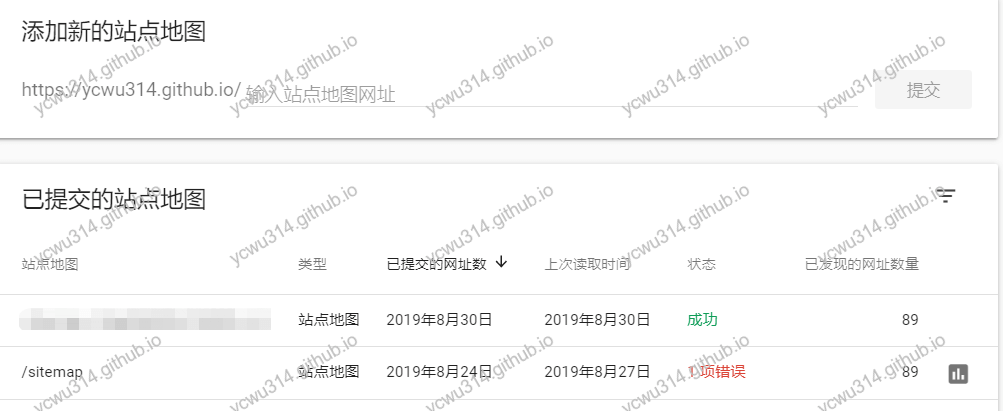
更改sitemap
sitemap告诉搜索引擎可以被爬取的文章地址。能够批量提交url。
对于垃圾爬虫文章站点来说,sitemap就相当于站点脱裤子了。
sitemap是一个约定,默认地址是/sitemap或者/sitemap.xml
绝大数的站点都会遵循这样的约定。当然这个路径是可以自定义的。
关闭归档页面
遍历归档页面也可以简单获取所有内容。至少目前来看,归档页面对我作用不大,直接在hexo的项目_config.yml关闭入口。
同时修改目录路径(也可以在部署脚本直接rm -f删除整个归档目录)。
动态修改归档页面路径
如果想保留归档页面,可以考虑每次部署的时候动态修改归档页面路径。这样旧的爬虫拿不到更新。 修改next主题的_config.yml
menu:
home: / || home
about: /about/ || user
archives:
结合travis ci,可以方便实现每次构建动态更新tags目录名字。
不过产生另一个问题:搜索引擎会索引大量的无效链接。 本身归档页面主要是给人看,而不是机器看的。页面上也只是其他文章的链接,因此不需要被索引。 虽然是动态生成归档路径,但是如果是一个pattern命名,可以直接写到robots.txt告诉爬虫不要抓取。
另一种方法是在归档页面使用noindex标记。原理参考使用“noindex”阻止搜索引擎将您的网页编入索引。
<meta name="robots" content="noindex">
- 修改themes\next\layout_layout.swig:
<head>
{% if noindex %}
<meta name="robots" content="noindex">
{% endif %}
- 修改themes\next\layout\archive.swig,在开头增加
{% set noindex = true %}
还可以应用到tags、categories。
关闭rss
流量也没有,rss也是多余的。直接在hexo的next主题关闭
rss: false
效果
发了几个测试文章,观察发现爬虫站点没有爬取。
下一步
遍历站点首页,也可以获取全部文章链接。下次在hexo模板上做个优化,不把链接写在超链接的href属性,改成JavaScript触发,增加静态解析的难度。 对于google爬虫来说,没有影响。
爬虫投毒:发布过时内容
如果觉得关闭sitemap、rss不方便,可以尝试发布无效内容,也叫爬虫投毒。在工作中,爬虫投毒更多用于竞争对手的防爬。 先新建一个文章,空的内容,提交,等垃圾爬虫收录之后,再编辑原来的文章,写入真正的内容。这个过程,需要几天时间。 前面提到,这类文章搬运工只会收录,不管更新。因此保护了站点内容。
但是写作体验就不好了。
文章正文增加版权声明
hexo next自带版权插件。但是爬虫根本不会抓取。要把版权内容写入到文章body才有用。
打开themes\next\layout\_macro\post.swig,搜索post-body,在这个div里面然后新增一个<p>来存放版权声明,写明作者、地址、授权问题。
本文作者{{ config.author }},未经允许请勿转载 <a href="{{ post.permalink }}">{{ post.title }}</a> : {{ post.permalink }}
爬虫识别这是hexo构建的站点,爬取的时候,就无脑解析<div class="post-body">。自然把这个版权声明也爬取进去了。
总结
下次聊聊字体反爬。