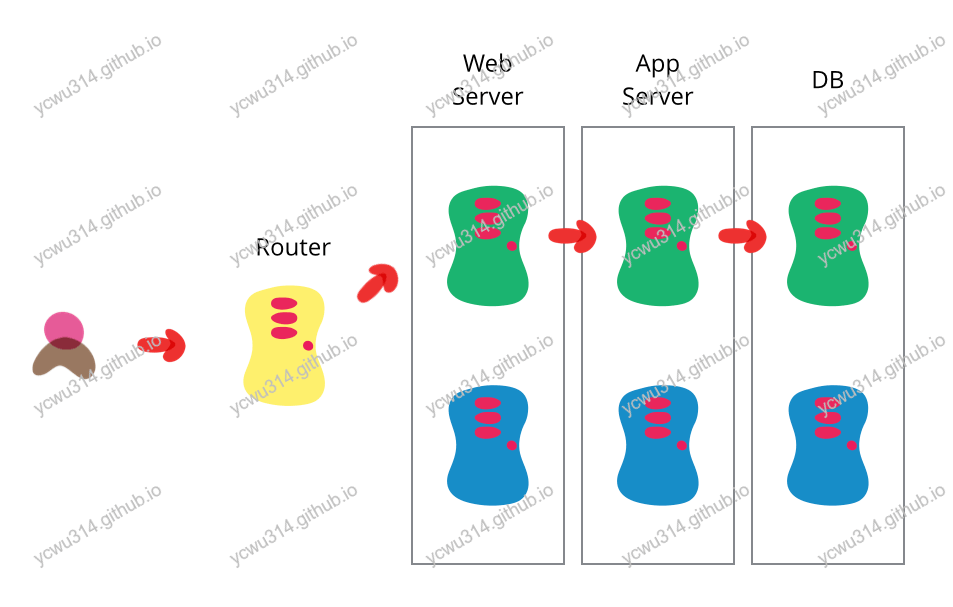
软件部署是一个重要的环节,有多重要,值得烧香保平安😀。 部署主要涉及的有:
- 不停服务发布
- 线上验证
- 失败回滚
一把梭部署

图片来源网络,侵删。
自信满满、或者已有跑路路线的朋友,可以使用此方式部署(开个玩笑~)。 一把梭部署看上去简单粗暴又高效,实际上相当危险:
- 一旦发现线上的包有问题,则整个集群都被污染了(扩大了错误影响面)
- 全量部署后才发现问题,已经没得回滚。或者回滚相当复杂
- 更艰难的是处理混滚期间的脏数据,让系统恢复一致性
切勿在生产环境中使用一把梭部署。
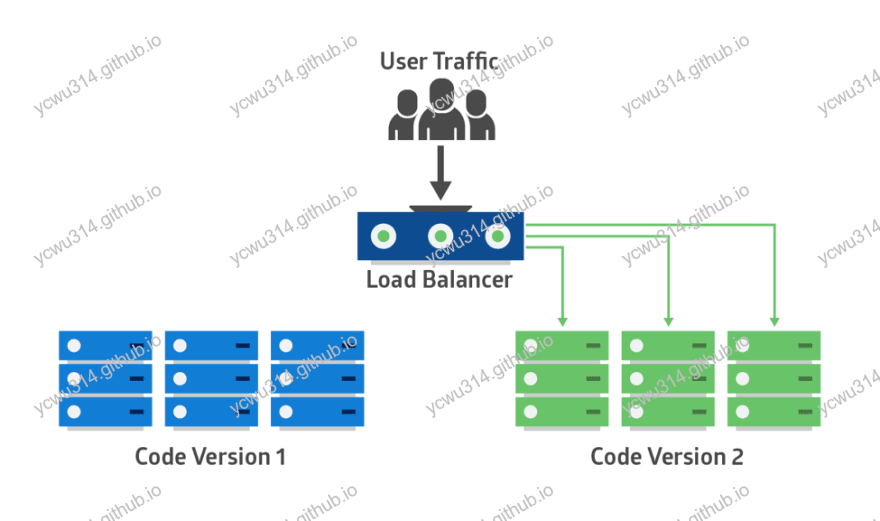
蓝绿部署,blue green deployment
引用Martin Fowler的图片BlueGreenDeployment
蓝绿部署环境分为2个,一个蓝,一个绿,并且都是生产配置。 假设一开始系统部署在蓝色环境,流量指向蓝色环境,现在要做升级部署。那么把最新代码部署在绿色环境,再把流量切换到绿色环境,做线上验证。 如果验证通过,则全量流量切换到绿色环境,使用绿色环境做这次的正式生产环境。 如果验证不通过,则流量切换回到蓝色环境。在绿色环境进行修复和验证。如此重复直到正式部署。 正式上线后,另一个环境的资源可以被回收,避免浪费。
优点:
- 做切换和部署简单
缺点:
- 资源消耗大(容器化可以简化问题)
- 为了做线上验证,切换了整个集群
数据同步问题
在落地中,数据一致性是比较麻烦的事情。在Martin Fowler的示意图中,部署2份数据库。但是会浪费资源,而且数据同步也是坑。只部署一份数据库,由蓝绿环境共用同一份数据库,遇到数据库修改的部署,也是麻烦。
因此,设计好表结构,避免日后修改,非常重要。 一点小技巧是,尽量做新增,而不是修改。新的扩展表、影子表、字段,回滚相对方便。
金丝雀发布(灰度发布),canary release
蓝绿部署,每次操作的单位是一个集群,粒度很大。 金丝雀发布(canary release),是蓝绿部署的一种改善。每次发布,只针对进群中少量的机器进行更新,以及验证。一旦线上验证通过,再对其余实例进行更新,放大流量。
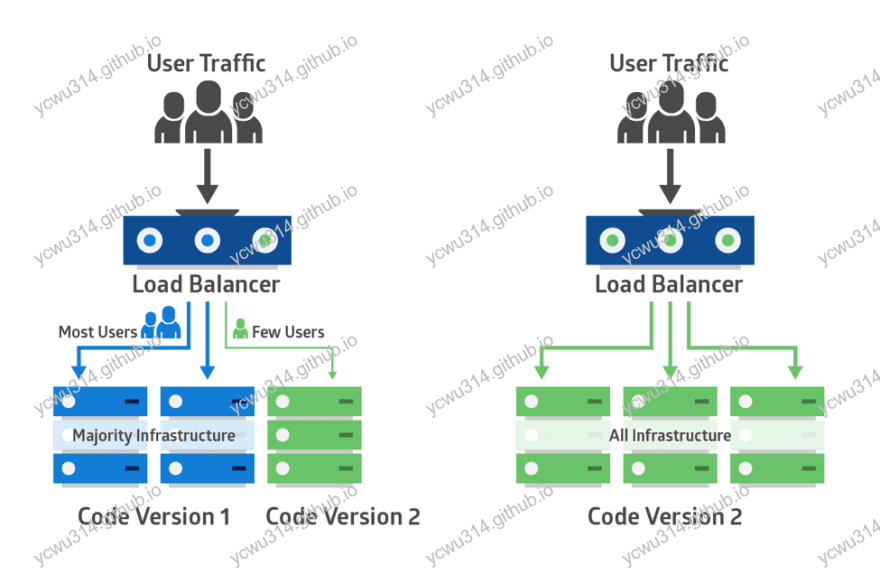
图片来源CANARY DEPLOYMENTS WITH SERVERLESS AND AWS CODE PIPELINE
从图上可以看到,金丝雀发布过程,会出现2个服务版本共存的状态,这个共存状态可能持续好一段时间。比如做A/B测试,验证新旧推荐算法对CTR的影响。
优点:
- 缩小线上验证粒度,比蓝绿部署更加安全
缺点:
- 因为每次只验证少量实例,需要有好的部署工具做滚动发布(rolling update)
共同的问题
除了一把梭部署方式,其他线上部署和验证都会遇到流量切换和验证问题。现在简单聊聊。
- DNS。更改出口DNS和内部调用DNS,把新流量引入到带验证机器上。操作简单,但是DNS更新有延迟问题。
- SLB(server side loadbalance)。在SLB层面切换流量。对SLB后边的服务切换快速快速生效。
- tcpcopy流量复制。直接把线上流量复制到测试机器。但是要改造业务和框架,防止流量被多次处理。
流量进入了待验证的新服务,还需要验证操作结果是否正确。怎么把特定流量和普通流量区分开来?
- 特殊固定账号。在验证阶段,使用特殊账号产生数据,并且跟踪。
- 特殊标记。在入口处加上特殊标记,比如
abtest=1,再利用全链路跟踪打点找到对应的结果。
如果出现问题需要回滚,要具体场景具体分析:
- 只读场景。只需要回滚上一个版本的代码即可。
- 已经修改了数据。如果是特殊固定账号创建的数据,通常可以直接删除。
- 真实用户创建的数据。只能根据具体情况,做业务补偿。
实践
第一次接触“蓝绿部署”的概念,是在《微服务设计》。实际工作中,使用的是金丝雀发布(灰度发布) + 滚动发布。