前言
监控体系里面有3个容易混淆的概念:logging、metrics和tracing。整理做下笔记。
logging, metrics and tracing
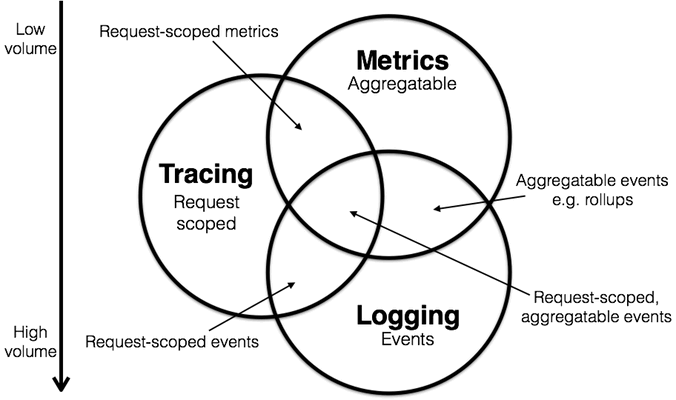
关注点
- logging: 记录离散事件(discrete events)。可以是纯文本、结构化、甚至是二进制的日志,用于记录某个时间点发生的事情。
- metrics: 对于一段时间内事件的观察指标(measurement over time)。通常是可以聚合(aggregatable)的指标,但也有例外,比如percentile、average。
- tracing: 展现系统中关联但是又离散的(related and discrete)事件流,因而是有序的(ordered)。通常用于分布式系统。
用途
- logging: 日志包含某个event的详细情况。例如一个error级别的日志详情。
- metrics: 可以发现观察指标的变化趋势,比如过去1 min http请求的失败率、平均响应时间。常见的指标有counter、gauge、histogram。
- tracing:用于发现跨服务调用的影响(identify cause across services)。比如一个request涉及多个分布式服务,如果request响应慢了,可以从tracing发现哪个调用环节慢了,成为瓶颈。
资源消耗
- logging: 跟记录流量和记录粒度成正比
- metrics: 固定的写流量(因为metrics只保留指标)
- tracing: 跟流量成正比
(logging and tracing generally increase volume with traffic)
为了减少资源消耗
- logging: 过滤掉不必要的event
- metrics: 粗粒度(coarser grain)指标
- tracing: 采样(sampling),而非记录所有跟踪事件
ps. adrian cole的ppt说metrics还可以通过read-your-writes来减少记录资源消耗,不是很理解。
关于logging
日志可以细分为多种类型:
Transaction logs
关键事务日志,比如跟钱相关的。
Request logs
http请求、数据库请求等。通常尽可能要记录,但丢失一小部分也不是大不了的事情。
Application logs
应用进程本身的日志,比如启动信息、后台任务等。
Debug logs
针对某些场景非常详细的debug日志。
小结
- logging: 记录详细的事件,例如异常信息
- metrics: 发现趋势,发送告警
- tracing: 分布式服务调用中分析慢请求