背景
一个count查询耗时超过1秒。 使用了pagehelper计算count。


中间是一堆上万个的ID列表。这个sql贴到文本文件,有200KB😂。
优化过程
套路:
- 子查询的
ORDER BY ID DESC可以去掉,节省时间。 - 子查询
SELECT A.*对于count来说是多余的,去掉。
SELECT COUNT(0) FROM VIDEODEV_INFO_VIEW A WHERE ( A.ADMINAREA_GB_CODE LIKE concat(44, '%') ) OR A.BITMAP_ID in (4970,3640) // in 是一堆ID列表
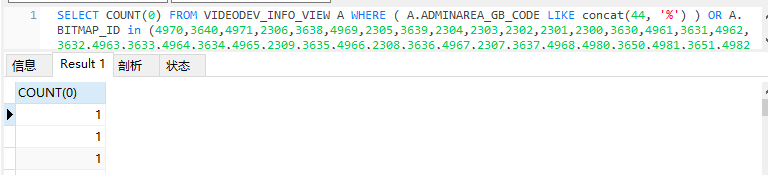
速度是很快很多,从1.2s降低到0.7s。 但是,根据count函数的语义,上面sql应该一个返回一行,数值是行数N,而不是不是返回N多行1。 于是把ID列表删除只剩下几个,发现count函数返回又符合预期。
这期间犯傻了,没有认证对比原来的sql,还以为是触发了mysql的什么bug,绕了很大的弯路。
最后在无意中才发现了id太长,里面还有group by语句
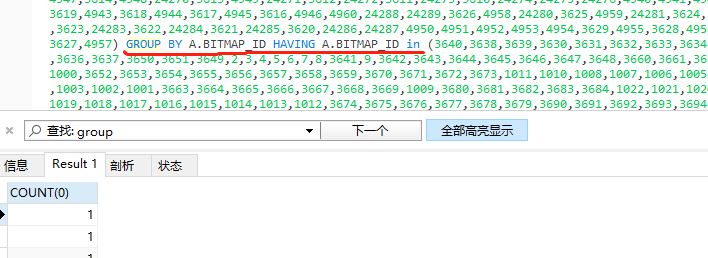
SELECT COUNT(0) FROM VIDEODEV_INFO_VIEW A WHERE ( A.ADMINAREA_GB_CODE LIKE concat(44, '%') ) OR A.BITMAP_ID in (4970,3640)
GROUP BY A.BITMAP_ID HAVING A.BITMAP_ID in (3640,3638)
因为bitmap_id是唯一的,导致group by之后,每个bitmap分组只有一条数据,最后执行count对每个bitmap_id分组计数,当然返回了一堆1了。
这个group by + having过滤太骚了。这时候找了源码来看
<select id="getCameraViewByOrgCodes" resultMap="DeviceResultMap">
SELECT A.*
FROM VIDEODEV_INFO_VIEW A
<where>
<if test="@com.xxxx.common.util.Ognl@isNotEmpty(deviceName)">
(
A.DEVICE_NAME LIKE concat('%', #{deviceName, jdbcType=VARCHAR}, '%')
OR A.VIDEODEV_GB_ID LIKE concat('%', #{deviceName, jdbcType=VARCHAR}, '%')
)
</if>
<if test="@com.xxxx.common.util.Ognl@isNotEmpty(listAdminAreaGbCode)">
<foreach item="item" index="index" collection="listAdminAreaGbCode" open="AND (" separator="OR" close=")">
A.ADMINAREA_GB_CODE LIKE concat(#{item}, '%')
</foreach>
</if>
<if test="@com.xxxx.common.util.Ognl@isNotEmpty(deviceParam)">
// 1
OR A.BITMAP_ID in ${deviceParam}
</if>
<if test="@com.xxxx.common.util.Ognl@isNotEmpty(userDeviceParam)">
// 2
GROUP BY A.BITMAP_ID
HAVING A.BITMAP_ID in ${userDeviceParam}
</if>
<if test="@com.xxxx.common.util.Ognl@isNotDefault(deviceSpeicaltypeDict)">
AND A.DEVICE_SPEICALTYPE_DICT = #{deviceSpeicaltypeDict,jdbcType=INTEGER}
</if>
</where>
ORDER BY A.ID DESC
</select>
注意1)和2)都是过滤bitmap_id字段,但是传入列表不一样。2)的操作结果,约等于使用指定bitmap列表做了过滤。
问了同事为什么在2)不用and过滤,一定要group by + having,没有回答清楚,说之前有bug。
本质问题是,业务含义(不展开了)理解和sql操作符号优先级。
or优先级比and低,如果2)直接用and,那么and先执行,再执行上面的or,导致比目标结果集大(之前版本的bug)。
为什么group by的结果就对呢?因为group by优先级比or低,后面再执行,实现了“过滤”。
至此,定位慢sql的原因了。
解决问题
- 去掉
group by + having,改用and - 适配优先级,上面几个条件用
()括住。涉及到mybatis if标签嵌套 - 更优化的改动是,根据两处bitmap_id的条件,分别拆开sql,但是导致应用复杂一些
SELECT count(0) FROM VIDEODEV_INFO_VIEW A WHERE (
( A.ADMINAREA_GB_CODE LIKE concat(44, '%') ) OR A.BITMAP_ID in (4970,364) // 这些条件被一对括号括住,保证优先级
)
AND A.BITMAP_ID in (4970,364)
这样修改后,原有数据量,count在0.5s - 0.6s 返回(因为有个like匹配,快不了)。
小结
这次sql优化经历有点粗心,中间浪费了不少时间。
- 认证对比sql
- 直接看源文件
都可以避免掉。